Lazy Ions Application
Application
This is the blog-post about the application called lazy ions. The
temporary web-page could be found here. The aim of the lazy ions is
to analyse the future trendsetters for the new papers released on the
arXiv.
I am using the Ada - Boosted classifier trained on the set of trendsetter vs. non-trendsetter papers and metadata downloaded from arXiv. The trendsetters are defined as the most cited authors in the period of last five years in certain area of research. The non-trendsetters are the authors that are not trendsetters but are still producing papers in given field.
My application lazy ions so far works only for hep-th field on arXiv.
I the future other areas will be included as well. You can check lazy ions
code on github.
The hep-th papers predicted to be trendsetters by my application:
Application details
The whole project is developed in PyCharm in conjunction with live script run in Jupyther. The project consists of four main steps:
- Getting raw data from arXiv
- Exploratory analysis
- Feature engineering, feature selection and Model building
- Model evaluation and prediction
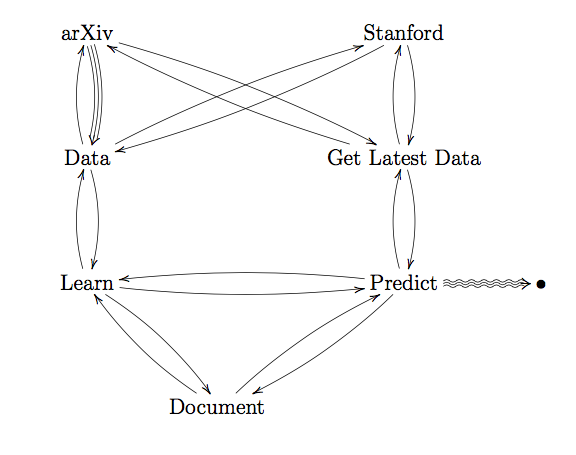
I addressed the points 1. to 4. by creating the Python module. The module
consists of five classes:
- class Data
- class GetLatestData
- class Document
- class Learn
- class Predict
The following diagram describes the interactions between classes and between classes and environment.
Exploratory analysis
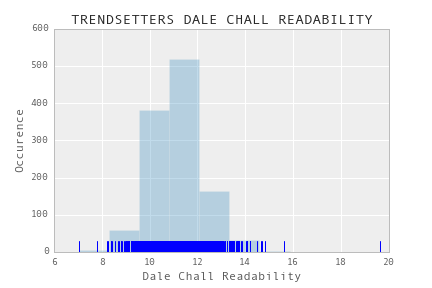
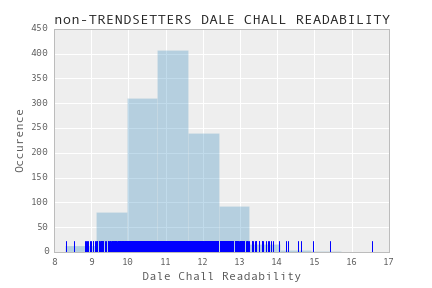
In my exploration I looked at various preliminary measures of trendsetting and non trendsetting papers. One interesting observation was that the Dale-Chall readability of “trendsetting” papers is quite different than the readability of “non-trendsetting” papers. I got the following distributions of readabilities:
For trending papers:
For non-trending papers:
Feature engineering, feature selection and Model building
Having downloaded the meta-data and actual pdf files from arXiv for trendsetters and non-trendsetters. I split the trendsetting papers to the papers belonging to the top trendsetting authors (the upper five per-cent). I call that set a golden standard. I have done that to have base to which I can calculate the cosine similarities of the rest of the papers to the golden standard. By this I engineered the global feature for each article. Moreover for each paper I calculated the local features (meaning related to the paper itself regardless the corpus). The following summarises all features calculated for each paper. By selecting following features I wanted to catch the formal structure together with factual structure of papers:
- cosine similarities to the golden standard
- equal sign densities of text
- equal sign densities of abstract
- Dale-Chall readabilities of text
- Dale-Chall readabilities of abstract
- number of lines density of text
- number of lines density of abstract
- length of the text
- length of the abstract
- pure text density of text
- pure text density of abstract
Note, by pure text density ((num. of words in pure text / (num. of words in the orig. text))) I mean the density of cleaned up text (text consisting only of factual information nouns).
Model evaluation and prediction
The aim of this project was to train the classifier. I picked the Ada-Boosted classifier. The reason was that I still had not enormously huge data set. So, in this project the scalability was not an issue. The Ada-Boost is considered the best out of box classifier. The creators got Gödel Prize for this algorithm.
Moreover I used this algorithm before in the work for the medical startup REVON.
I trained the scikit-learn version of the Ada_Boost classifier with a grid search. I split my data into three groups training (70 per-cent) testing (20 per-cent) validation (10 per-cent).
After training I got the classifier with accuracy on validation set to be around 67 per-cent.
By that classifier I predicted the papers whose links you can find at the
top of the website. The prediction has been made on the most recent hep-th papers
from arXiv.
Future work proposal
For the future work I propose the following:
- Get more data with precise number of citations for each paper
- More model space exploration
- Extend the algorithm for different (other than
hep-th) arXiv sections - Extend the algorithm for other media (other than arXiv)
- Introduce the online learning, with proper implementation of exploration vs. exploitation
- Personalised version
- Use the algorithm as trendsetting-nes estimator for authors